
*
Structured 3D Latents
for Scalable and Versatile 3D Generation
* Generated by TRELLIS, using its image to 3D assets cabilities.
TL;DR: A native 3D generative model built on a unified Structured Latent representation and Rectified Flow Transformers,
enabling versatile and high-quality 3D asset creation.
We introduce a novel 3D generation method for versatile and high-quality 3D asset creation.
The cornerstone is a unified Structured LATent (SLAT) representation which allows decoding to different output formats, such as Radiance Fields, 3D Gaussians, and meshes.
This is achieved by integrating a sparsely-populated 3D grid with dense multiview visual features extracted from a powerful vision foundation model,
comprehensively capturing both structural (geometry) and textural (appearance) information while maintaining flexibility during decoding.
We employ rectified flow transformers tailored for SLAT as our 3D generation models and train models with up to 2 billion parameters on a large 3D asset dataset of 500K diverse objects.
Our model generates high-quality results with text or image conditions, significantly surpassing existing methods, including recent ones at similar scales.
We showcase flexible output format selection and local 3D editing capabilities which were not offered by previous models.
Code, model, and data will be released.
NOTE: The appearance and geometry shown in this page are rendered from 3D Gaussians and meshes, respectively.
GLB files are extracted by baking appearance from 3D Gaussians to meshes.
Generation | Text to 3D Asset
All text prompts are generated by GPT-4. Click on the cards to view extracted GLB files.
Generation | Image to 3D Asset
Image prompts are either generated by DALL-E 3 or extracted from SA-1B. Click on the cards to view extracted GLB files.
TRELLIS
can generates variants of a given 3D asset coherent with given text prompts.
Editing | Local Manipulation
TRELLIS
can manipulate targeted local regions of a given 3D asset according to given text or image prompts.
Application | 3D Art Designs
Compositing the high-quality 3D assets generated by TRELLIS,
complex and vibrant 3D art designs can be created with ease.
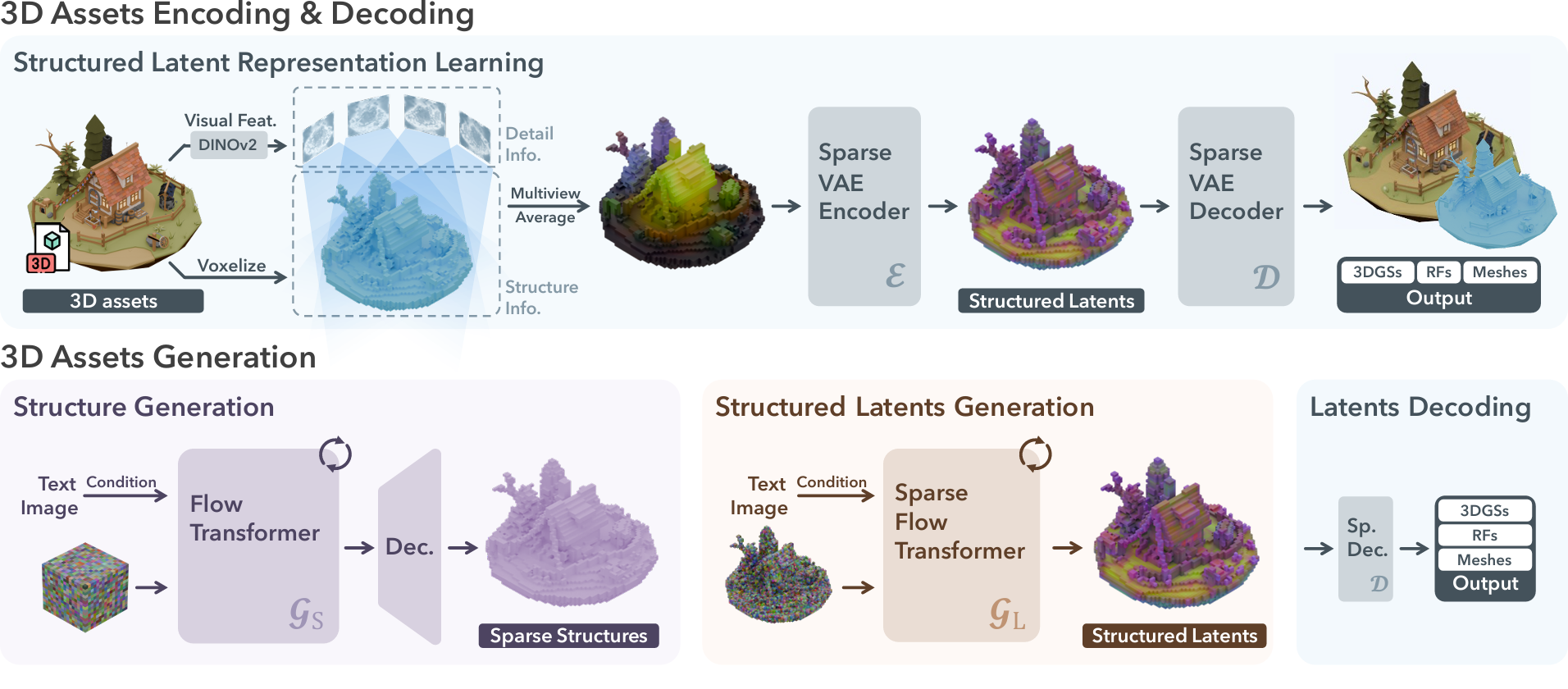
We introduce Structured LATents (SLAT),
a unified 3D latent representation for high-quality, versatile 3D generation. SLAT
marries sparse structures with powerful visual representations. It defines local latents on active voxels intersecting the object’s surface.
The local latents are encoded by fusing and processing image features from densely rendered views of the 3D asset, while attaches them onto active voxels.
These features, derived from powerful pretrained vision encoders, capture detailed geometric and visual characteristics, complementing the coarse structure provided by the active voxels.
Different decoders can then be applied to map SLAT to diverse 3D representations of high quality.
Building on SLAT, we train a family of large 3D generation models, dubbed TRELLIS, with text prompts or images as conditions.
A two stage pipeline is applied which first generates the sparse structure of SLAT, followed by generating the latent vectors for non-empty cells.
We employ rectified flow transformers as our backbone models and adapt them properly to handle the sparsity in SLAT.
We train Trellis with up to 2 billion parameters on a large dataset of carefully-collected 3D assets.
TRELLIS can create high-quality 3D assets with detailed geometry and vivid texture, significantly surpassing previous methods.
Moreover, it can easily generate 3D assets with different output formats to meet diverse downstream requirements.
If you find our work useful, please consider citing:
@article{xiang2024structured,
title = {Structured 3D Latents for Scalable and Versatile 3D Generation},
author = {Xiang, Jianfeng and Lv, Zelong and Xu, Sicheng and Deng, Yu and Wang, Ruicheng and
Zhang, Bowen and Chen, Dong and Tong, Xin and Yang, Jiaolong},
journal = {arXiv preprint arXiv:2412.01506},
year = {2024}
}


