ARC Prize remains undefeated.
New ideas still needed.
OpenAI’s new o3 system – trained on the ARC-AGI-1 Public Training set – has scored a breakthrough 75.7% on the Semi-Private Evaluation set at our stated public leaderboard $10k compute limit. A high-compute (172x) o3 configuration scored 87.5%.

This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. For context, ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.
The mission of ARC Prize goes beyond our first benchmark: to be a North Star towards AGI. And we’re excited to be working with the OpenAI team and others next year to continue to design next-gen, enduring AGI benchmarks.
ARC-AGI-2 (same format – verified easy for humans, harder for AI) will launch alongside ARC Prize 2025. We’re committed to running the Grand Prize competition until a high-efficiency, open-source solution scoring 85% is created.
Read on for the full testing report.
OpenAI o3 ARC-AGI Results
We tested o3 against two ARC-AGI datasets:
- Semi-Private Eval: 100 private tasks used to assess overfitting
- Public Eval: 400 public tasks
At OpenAI’s direction, we tested at two levels of compute with variable sample sizes: 6 (high-efficiency) and 1024 (low-efficiency, 172x compute).
Here are the results.
| Set | Tasks | Efficiency | Score | Retail Cost | Samples | Tokens | Cost/Task | Time/Task (mins) |
|---|---|---|---|---|---|---|---|---|
| Semi-Private | 100 | High | 75.7% | $2,012 | 6 | 33M | $20 | 1.3 |
| Semi-Private | 100 | Low | 87.5% | – | – | – | – | – |
| Public | 400 | High | 82.8% | $6,677 | 6 | 111M | $17 | N/A |
| Public | 400 | Low | 91.5% | – | – | – | – | — |
- Note: OpenAI has requested that we not publish the high-compute costs. The amount of compute was roughly 172x the low-compute configuration.
Due to variable inference budget, efficiency (e.g., compute cost) is now a required metric when reporting performance. We’ve documented both the total costs and the cost per task as an initial proxy for efficiency. As an industry, we’ll need to figure out what metric best tracks efficiency, but directionally, cost is a solid starting point.
The high-efficiency score of 75.7% is within the budget rules of ARC-AGI-Pub (costs <$10k) and therefore qualifies as 1st place on the public leaderboard!
The low-efficiency score of 87.5% is quite expensive, but still shows that performance on novel tasks does improve with increased compute (at least up to this level.)
Despite the significant cost per task, these numbers aren’t just the result of applying brute force compute to the benchmark. OpenAI’s new o3 model represents a significant leap forward in AI’s ability to adapt to novel tasks. This is not merely incremental improvement, but a genuine breakthrough, marking a qualitative shift in AI capabilities compared to the prior limitations of LLMs. o3 is a system capable of adapting to tasks it has never encountered before, arguably approaching human-level performance in the ARC-AGI domain.
Of course, such generality comes at a steep cost, and wouldn’t quite be economical yet: you could pay a human to solve ARC-AGI tasks for roughly $5 per task (we know, we did that), while consuming mere cents in energy. Meanwhile o3 requires $17-20 per task in the low-compute mode. But cost-performance will likely improve quite dramatically over the next few months and years, so you should plan for these capabilities to become competitive with human work within a fairly short timeline.
o3’s improvement over the GPT series proves that architecture is everything. You couldn’t throw more compute at GPT-4 and get these results. Simply scaling up the things we were doing from 2019 to 2023 – take the same architecture, train a bigger version on more data – is not enough. Further progress is about new ideas.
So is it AGI?
ARC-AGI serves as a critical benchmark for detecting such breakthroughs, highlighting generalization power in a way that saturated or less demanding benchmarks cannot. However, it is important to note that ARC-AGI is not an acid test for AGI – as we’ve repeated dozens of times this year. It’s a research tool designed to focus attention on the most challenging unsolved problems in AI, a role it has fulfilled well over the past five years.
Passing ARC-AGI does not equate achieving AGI, and, as a matter of fact, I don’t think o3 is AGI yet. o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.
Furthermore, early data points suggest that the upcoming ARC-AGI-2 benchmark will still pose a significant challenge to o3, potentially reducing its score to under 30% even at high compute (while a smart human would still be able to score over 95% with no training). This demonstrates the continued possibility of creating challenging, unsaturated benchmarks without having to rely on expert domain knowledge. You’ll know AGI is here when the exercise of creating tasks that are easy for regular humans but hard for AI becomes simply impossible.
What’s different about o3 compared to older models?
Why does o3 score so much higher than o1? And why did o1 score so much higher than GPT-4o in the first place? I think this series of results provides invaluable data points for the ongoing pursuit of AGI.
My mental model for LLMs is that they work as a repository of vector programs. When prompted, they will fetch the program that your prompt maps to and “execute” it on the input at hand. LLMs are a way to store and operationalize millions of useful mini-programs via passive exposure to human-generated content.
This “memorize, fetch, apply” paradigm can achieve arbitrary levels of skills at arbitrary tasks given appropriate training data, but it cannot adapt to novelty or pick up new skills on the fly (which is to say that there is no fluid intelligence at play here.) This has been exemplified by the low performance of LLMs on ARC-AGI, the only benchmark specifically designed to measure adaptability to novelty – GPT-3 scored 0, GPT-4 scored near 0, GPT-4o got to 5%. Scaling up these models to the limits of what’s possible wasn’t getting ARC-AGI numbers anywhere near what basic brute enumeration could achieve years ago (up to 50%).
To adapt to novelty, you need two things. First, you need knowledge – a set of reusable functions or programs to draw upon. LLMs have more than enough of that. Second, you need the ability to recombine these functions into a brand new program when facing a new task – a program that models the task at hand. Program synthesis. LLMs have long lacked this feature. The o series of models fixes that.
For now, we can only speculate about the exact specifics of how o3 works. But o3’s core mechanism appears to be natural language program search and execution within token space – at test time, the model searches over the space of possible Chains of Thought (CoTs) describing the steps required to solve the task, in a fashion perhaps not too dissimilar to AlphaZero-style Monte-Carlo tree search. In the case of o3, the search is presumably guided by some kind of evaluator model. To note, Demis Hassabis hinted back in a June 2023 interview that DeepMind had been researching this very idea – this line of work has been a long time coming.
So while single-generation LLMs struggle with novelty, o3 overcomes this by generating and executing its own programs, where the program itself (the CoT) becomes the artifact of knowledge recombination. Although this is not the only viable approach to test-time knowledge recombination (you could also do test-time training, or search in latent space), it represents the current state-of-the-art as per these new ARC-AGI numbers.
Effectively, o3 represents a form of deep learning-guided program search. The model does test-time search over a space of “programs” (in this case, natural language programs – the space of CoTs that describe the steps to solve the task at hand), guided by a deep learning prior (the base LLM). The reason why solving a single ARC-AGI task can end up taking up tens of millions of tokens and cost thousands of dollars is because this search process has to explore an enormous number of paths through program space – including backtracking.
There are however two significant differences between what’s happening here and what I meant when I previously described “deep learnin-guided program search” as the best path to get to AGI. Crucially, the programs generated by o3 are natural language instructions (to be “executed” by a LLM) rather than executable symbolic programs. This means two things. First, that they cannot make contact with reality via execution and direct evaluation on the task – instead, they must be evaluated for fitness via another model, and the evaluation, lacking such grounding, might go wrong when operating out of distribution. Second, the system cannot autonomously acquire the ability to generate and evaluate these programs (the way a system like AlphaZero can learn to play a board game on its own.) Instead, it is reliant on expert-labeled, human-generated CoT data.
It’s not yet clear what the exact limitations of the new system are and how far it might scale. We’ll need further testing to find out. Regardless, the current performance represents a remarkable achievement, and a clear confirmation that intuition-guided test-time search over program space is a powerful paradigm to build AI systems that can adapt to arbitrary tasks.
What comes next?
First of all, open-source replication of o3, facilitated by the ARC Prize competition in 2025, will be crucial to move the research community forward. A thorough analysis of o3’s strengths and limitations is necessary to understand its scaling behavior, the nature of its potential bottlenecks, and anticipate what abilities further developments might unlock.
Moreover, ARC-AGI-1 is now saturating – besides o3’s new score, the fact is that a large ensemble of low-compute Kaggle solutions can now score 81% on the private eval.
We’re going to be raising the bar with a new version – ARC-AGI-2 – which has been in the works since 2022. It promises a major reset of the state-of-the-art. We want it to push the boundaries of AGI research with hard, high-signal evals that highlight current AI limitations.
Our early ARC-AGI-2 testing suggests it will be useful and extremely challenging, even for o3. And, of course, ARC Prize’s objective is to produce a high-efficiency and open-source solution in order to win the Grand Prize. We currently intend to launch ARC-AGI-2 alongside ARC Prize 2025 (estimated launch: late Q1).
Going forward, the ARC Prize Foundation will continue to create new benchmarks to focus the attention of researchers on the hardest unsolved problems on the way to AGI. We’ve started work on a third-generation benchmark which departs completely from the 2019 ARC-AGI format and incorporates some exciting new ideas.
Get Involved: Open-Source Analysis
Today, we’re also releasing high-compute, o3-labeled tasks and would like your help to analyze them. In particular, we are very curious about the ~9% set of Public Eval tasks o3 was unable to solve, even with lots of compute, yet are straighforward for humans.
We invite the community to help us assess the characteristics of both solved and unsolved tasks.
To get your ideas flowing, here are 3 examples of tasks unsolved by high-compute o3.
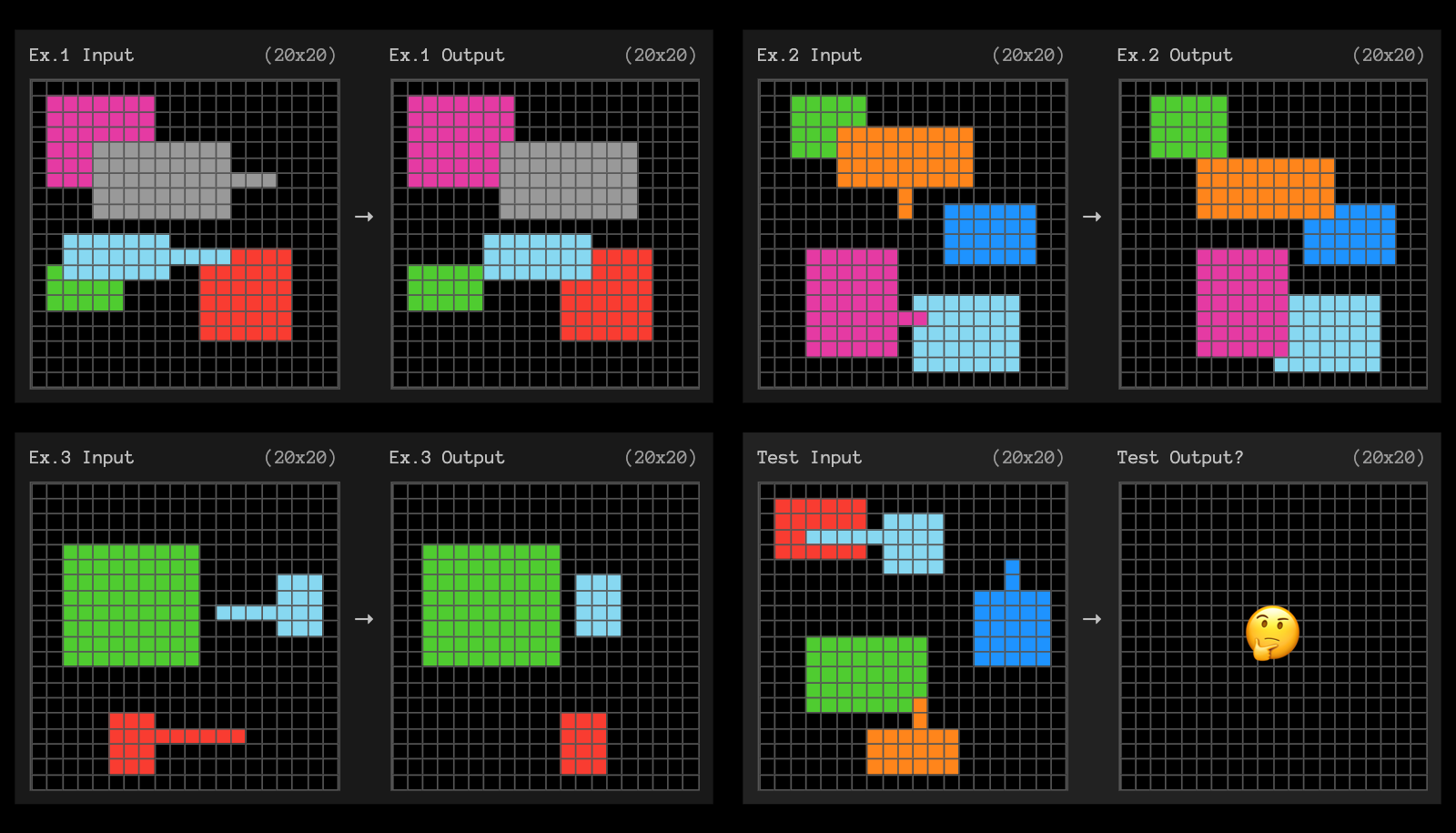
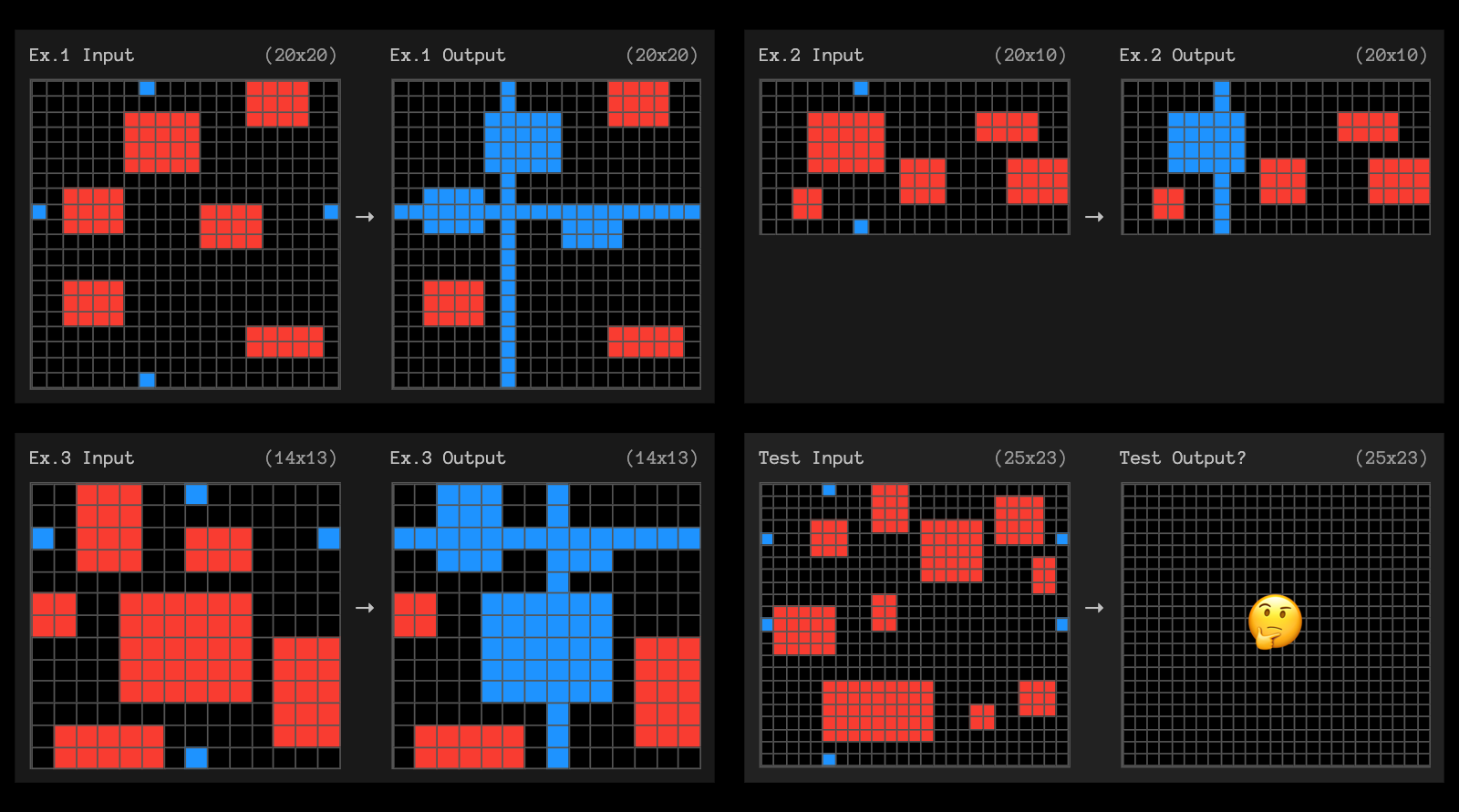

See our full set of o3 testing data.
We’ve also created a new channel in our Discord named oai-analysis and we’d love to hear your analysis and insights there. Or tag us on X/Twitter @arcprize.
Conclusions
To sum up – o3 represents a significant leap forward. Its performance on ARC-AGI highlights a genuine breakthrough in adaptability and generalization, in a way that no other benchmark could have made as explicit.
o3 fixes the fundamental limitation of the LLM paradigm – the inability to recombine knowledge at test time – and it does so via a form of LLM-guided natural language program search. This is not just incremental progress; it is new territory, and it demands serious scientific attention.