
Introduction
Feed readers are the best way to follow blogs and news, but the RSS feeds they rely on are not always easily found.
To make finding feeds easier, I developed the Lighthouse Feed Finder tool. It uses a variety of mechanisms to search for RSS feeds for the given website.
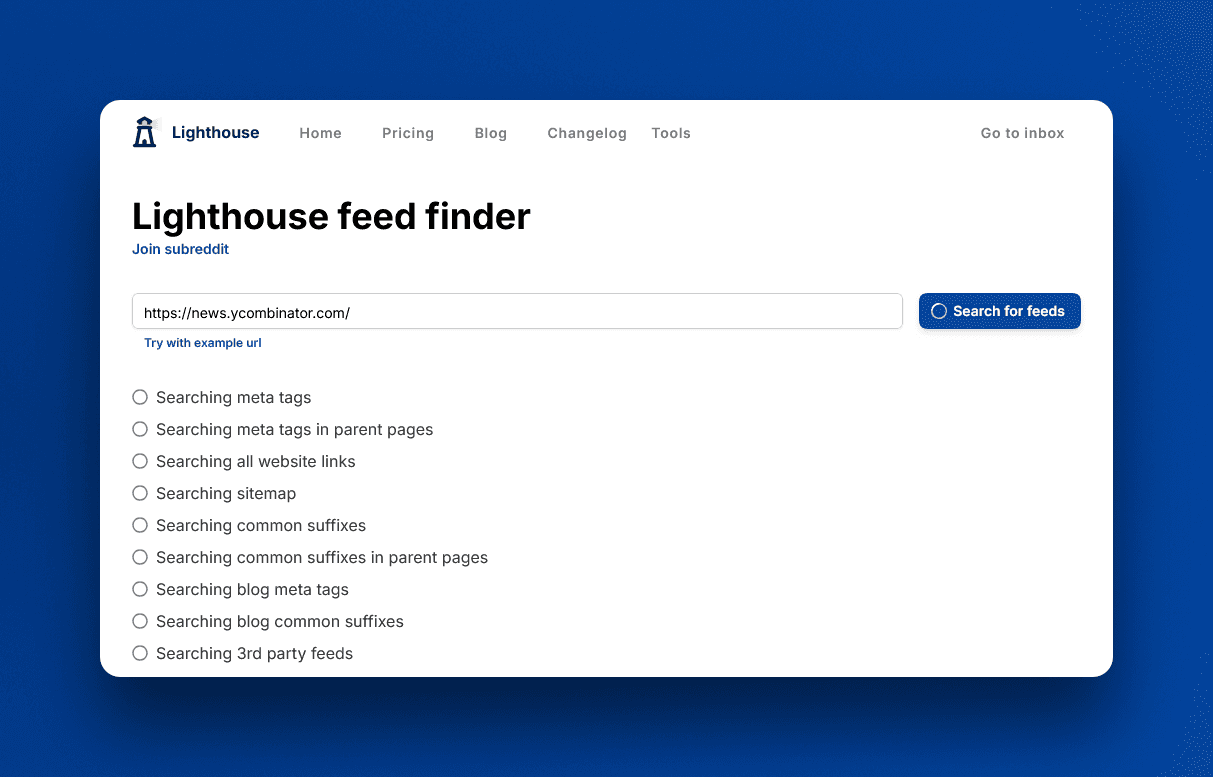
The goal of the Feed Finder is that if an RSS feed exists for the website, it finds it. Achieving this perfectly is impossible because there are countless ways RSS feeds can be published, but the tool comes close.
RSS icon as default way for linking to feeds
Over the years, the RSS icon has become a quasi-standard for linking to RSS feeds. These icons usually link directly to the feed URL.

Only a fraction of websites that publish RSS feeds advertise them in this manner. Some sites have dedicated pages that list their RSS feeds, and many more don’t link to their feeds at all.
Often website owners don’t even know that they publish RSS feeds because the software they use does it automatically.
WordPress and Substack, for example, publish them with the suffix /feed, and the author doesn’t have to do anything to make that happen.
RSS autodiscovery as standard for finding feeds
While many websites don’t display links to their RSS feeds, most add metadata that provides the feed URL. Software like WordPress and Substack can do that automatically, so RSS feeds are available much more often through metadata than via visible links on the page.
In the head section of the HTML, websites add a link tag with type="application/rss+xml" and an href attribute that links to the feed.
Other software can look for this specific link tag and get the RSS feed URL from it. This method is called RSS autodiscovery.
Virtually all feed readers implement it, making it possible to automatically find the RSS URL after a user enters the website they want to follow. In most cases at least.
There are websites that publish RSS feeds, but the standard way of finding them doesn’t work. If feed readers only implement RSS autodiscovery, they will incorrectly say that the website doesn’t have a feed.
This is where the advanced methods come into play. You can do them yourself, though it will be tedious, or use the Lighthouse Feed Finder to check them automatically.
Advanced methods for finding RSS feeds
Not all websites include metadata that specifies their RSS feeds, and when they do it may only appear on certain pages. Patterns I’ve seen are that metadata is found on blog or news sections. Even then, it might only be present on the main blog page rather than on individual articles or posts. Sometimes, though rarely, the RSS feed is not linked anywhere and the only way to find it is by guessing.
Finding other pages that link to the RSS feed
If a website provides RSS feeds and the current page doesn’t include metadata referencing it, usually there are other pages that do.
Therefore, one effective method is to check if RSS autodiscovery works on other pages of the website.
Checking parent URLs
If the provided URL is not the homepage but a specific page, it’s possible to check the parent pages.
For example, for an article page like https://personal.site/blog/article-1, the parent URLs would be
https://personal.site/bloghttps://personal.site
Both pages might link to the RSS feed.
Finding blog URL and checking alternate links
Blog or news pages are the most likely to link the RSS feed, even if the homepage doesn’t. Finding these pages and checking if they include the feed in the metadata has a good chance of success.
For example, if the site https://company.website is entered, it would check
https://company.website/newshttps://company.website/blog
There are many more suffixes to try, but there’s no point having a list with hundreds of URLs here. news and blog are relatively standard in English, but if websites are in another language they usually use different words.
This situation – where the homepage doesn’t link to the RSS feed – is most often the case with websites where the blog is not the main purpose. Company websites, for example, usually have other important sections like documentation (e.g. https://company.site/documentation/getting-started) that have nothing to do with the blog, and therefore don’t link to the blog’s RSS feed.
Checking sitemap
The sitemap is an XML file designed to contain all pages of a website. While sitemaps do not always include RSS feeds, in some cases they do. When RSS autodiscovery isn’t implemented at all, checking the sitemap is a good next step.
Sitemaps contain a huge number of URLs. Checking all of them to see if they reference a feed could take a long time.
Applying a heuristic to narrow down the possible URLs reduces the effort. A good heuristic is to check only URLs that include the keywords xml, rss, atom, and feed.
Checking all links on the website
It is possible that the RSS feed is not included in the website’s metadata but is instead linked within the site’s visible content. In such cases, examining all visible links will find the feed.
I have not yet come across such a case, but the Lighthouse Feed Finder implements it anyway.
Since a website can contain many links – similar to sitemaps though usually not quite as many – the same heuristic is applied.
Guessing the feed URL
If the RSS feed is not linked at all, the only remaining way is to try and guess the URL. This only works if the feed URL is behind a relatively common suffix, if it’s anything exotic, then it’s impossible to find.
By ‘impossible,’ I mean it would require too much effort. It is, of course, possible to brute-force and try every possible path, but it would take ages.
Checking common suffixes
Most RSS feeds are behind a relatively small set of paths. There are exceptions, but they are few and far between.
At the time of writing, the suffixes the Lighthouse feed finder uses are: /feed, /rss, /atom, /rss.xml, /atom.xml, /feed.xml, /feed.rss, /feed.atom, /feed.rss.xml, /feed.atom.xml, /index.xml, /index.rss, /index.atom, /index.rss.xml, /index.atom.xml, ?format=rss, ?format=atom, ?rss=1, ?atom=1, ?feed=rss, ?feed=rss2, ?feed=atom, .rss.
The exact location of the RSS feed varies for each website. Some have it directly under the homepage (e.g. https://web.site/feed) while others have it under the blog main page (e.g. https://web.site/blog/feed). There are other options, but these are the most common ones.
Because of that, the Feed Finder doesn’t just check the suffixes of the provided URL, but also of parent pages and potential blog URLs.
For example, if https://company.site/documentation/getting-started was entered, it would try all suffixes for the following URLs
Provided URL: https://company.site/documentation/getting-started
Parent pages
https://company.site/documentationhttps://company.site
Blog pages
https://company.site/newshttps://company.site/blog- And others
Checking third-party feeds
The most reliable feeds are the ones published by the websites themselves. This is why the Lighthouse Feed Finder gives them precedence and looks for them first.
However, some websites don’t provide RSS feeds. To address this, several third-party services generate RSS feeds for these sites. Some of them make their generated feeds public and allow people to use them. The largest one is OpenRSS.
Checking these as a last resort can get you a feed even if the website doesn’t provide one.
Topic-specific feeds
Most websites provide at most one RSS feed, but some websites provide RSS feeds for sub-sections of their website. This is most common with news sites that publish stories about different topics. They often provide dedicated feeds for each topic.
Usually every topic has a dedicated main page, for example https://news.site/technology and https://news.site/politics.
In this case, the technology and politics feeds will be linked on the respective page, but not on the other.
For example, if https://news.site/technology is entered, the Lighthouse Feed Finder will find the technology feed and the main news feed (usually linked at https://news.site), but won’t find the politics feed.
Crawling the whole domain
An option to find all feeds of a website is by crawling the whole domain, checking out every page, and applying the methods described here to each one.
While certainly possible, it’s not feasible to do at scale, with a public tool.
Bot protection and denial-of-service
The methods described here primarily involve checking numerous different URLs. The checked website will receive hundreds of requests in a short timespan. Even if the purpose is benign and the intention good, it doesn’t change the fact that it may look like a DOS attack.
To prevent websites being hit with the barrage of requests more than once per hour, the Lighthouse Feed Finder caches requests.
However, bot protection might still kick in, or it might be triggered from the start if set to be sufficiently strong. In that case, it would be impossible for such a tool to do its job because it can’t access the content.
Conclusion
There are more ways to find RSS feeds, and over time the Lighthouse Feed Finder will implement them all.
A stopgap is always to generate your own RSS feed based on the HTML of the website. It’s more error-prone, because it relies on the structure of the website, which might change, but in some cases it’s the only way.
Lighthouse will get that feature in the near future.
If you try the Feed Finder and it doesn’t find the feed even though you know it has one, I would be grateful if you either write me an email at dominik@lighthouseapp.io or add a comment to this post in the lighthouseapp subreddit. Ideally the website and RSS feed URL, but if you only have the website it’s also appreciated.
This will help me make the Feed Finder better.


