
TL;DR:
In this article, we discuss the practice of Rust error handling topic in GreptimeDB and shares possibly future work in the end.
Topics including: (1) How to build a cheaper yet more accurate error stack to replace system backtrace; (2) How to organize errors in large projects; (3) How to print errors in different schemes to log and end users.
An error in GreptimeDB might look like this:
0: Foo error, at src/common/catalog/src/error.rs:80:10
1: Bar error, at src/common/function/src/error.rs:90:10
2: Root cause, invalid table name, at src/common/catalog/src/error.rs:100:10Introduce
Understanding Error in Rust
Rust’s error handling is centered around the Result enum, where E typically (but unnecessarily) extends std::error::Error.
pub enum Result<T, E> {
/// Contains the success value
Ok(T),
/// Contains the error value
Err(E),
}This blog shares our experience organizing variant types of Error in a complex system like GreptimeDB, from how an error is defined to how to log the error or present it to end-users. Such a system is composed of multiple components with their own Error definitions.
Status Quo of Rust’s Error Handling
A few standard libraries in Rust provide Error structs that implement std::error::Error, like std::io::Error or std::fmt::Error. But developers would usually define custom errors for their project, as either they want to express the application specific error info, or there is a necessity to group multiple errors in an enum.
Since the std::error::Error trait is not quite complicated, it’s easy to implement manually for one custom error type. However, you usually won’t want to do so. Because as error variants grow, it would be very hard to work with the flooding template code.
Nowadays, there are some widely used utility crates to help work with customized error types. For example, thiserror and anyhow are developed by the famous Rust wizard @dtolnay, with the distinction that thiserror is mainly for libraries and anyhow is for binaries. This rule suits most of the cases.
But for projects like GreptimeDB, where we divide the entire workspace into several individual sub-crates, we need to define one error type for each crate while keeping a streamlined combination. Neither thiserror nor anyhow can achieve this easily.
Hence, we chose another crate, snafu, to instrument our error system. It’s like a combination of thiserror and anyhow. thiserror provides a convenient macro to define custom error types, with display, source, and some context fields. And anyhow gives a Context trait that can easily transform from one underlying error into another with a new context.
thiserror mainly implements the std::convert::From trait for your error types, so that you can simply use ? to propagate the error you receive. Consequently, this also means you cannot define two error variants from the same source type. Considering you are performing some I/O operations, you won’t know whether an error is generated in the write path or the read path. This is also an important reason we don’t use thiserror: the context is blurred in type.
Stacking the Error
Design Goals
In the real world, knowing barely the root cause of error is inadequate. Suppose we are building a protocol component in GreptimeDB. It reads messages from the network, decodes them, performs some operations, and then sends them. We may encounter errors from several aspects:
enum Error{
ReadSocket(hyper::Error),
DecodeMessage(serde_json::Error),
Operation(GreptimeError),
EncodeMessage(serde_json::Error),
WriteSocket(hyper::Error),
}One possible error message we can get is: DecodeMessage(serde_json: invalid character at 1). However, in a specific code snippet, there can be more than 10 places where decoding the message (and thus throw this error)! How can we figure out in which step we see the invalid character?
So, despite the error itself telling what has happened, if we want to have a clue on where this error occurs and if we should pay attention to it, we need the error to carry more information. For comparison, here is an example of an error log you might see from GreptimeDB.
Failed to handle protocol
0: Failed to handle incoming content, query: blabla, at src/protocol/handler.rs:89:22
1: Failed to reading next message at queue 5 of 10, at src/protocol/loop.rs:254:14
2: Failed to decode `01010001001010001` to ProtocolHeader, at src/protocol/codec.rs:90:14
3: serde_json(invalid character at position 1)A good error report is not only about how it gets constructed, but what is more important, to tell what human can understand from its cause and trace. We call it Stacked Error. It should be intuitive and you must have seen a similar format elsewhere like backtrace.
From this log, it’s easy to know the entire thing with full context, from the user-facing behavior to the root cause. Plus the exact line and column number of where each error is propagated. You will know that this error is “from the query “blabla”, the fifth package’s header is corrupted”. It’s likely to be invalid user input and we may not need to handle it from the server side.
This example shows the critical information that an error should contain:
- The root cause that tells what is happening.
- The full context stack that can be used in debugging or figuring out where the error occurs.
- What happens from the user’s perspective. Decide whether we need to expose the error to users.
The first root cause is often clear in many cases, like the DecodeMessage example above, as long as the library or function we used implements their error type correctly. But only having the root cause can be not enough.
Here is another evidence from Delta Lake developed by Databricks:
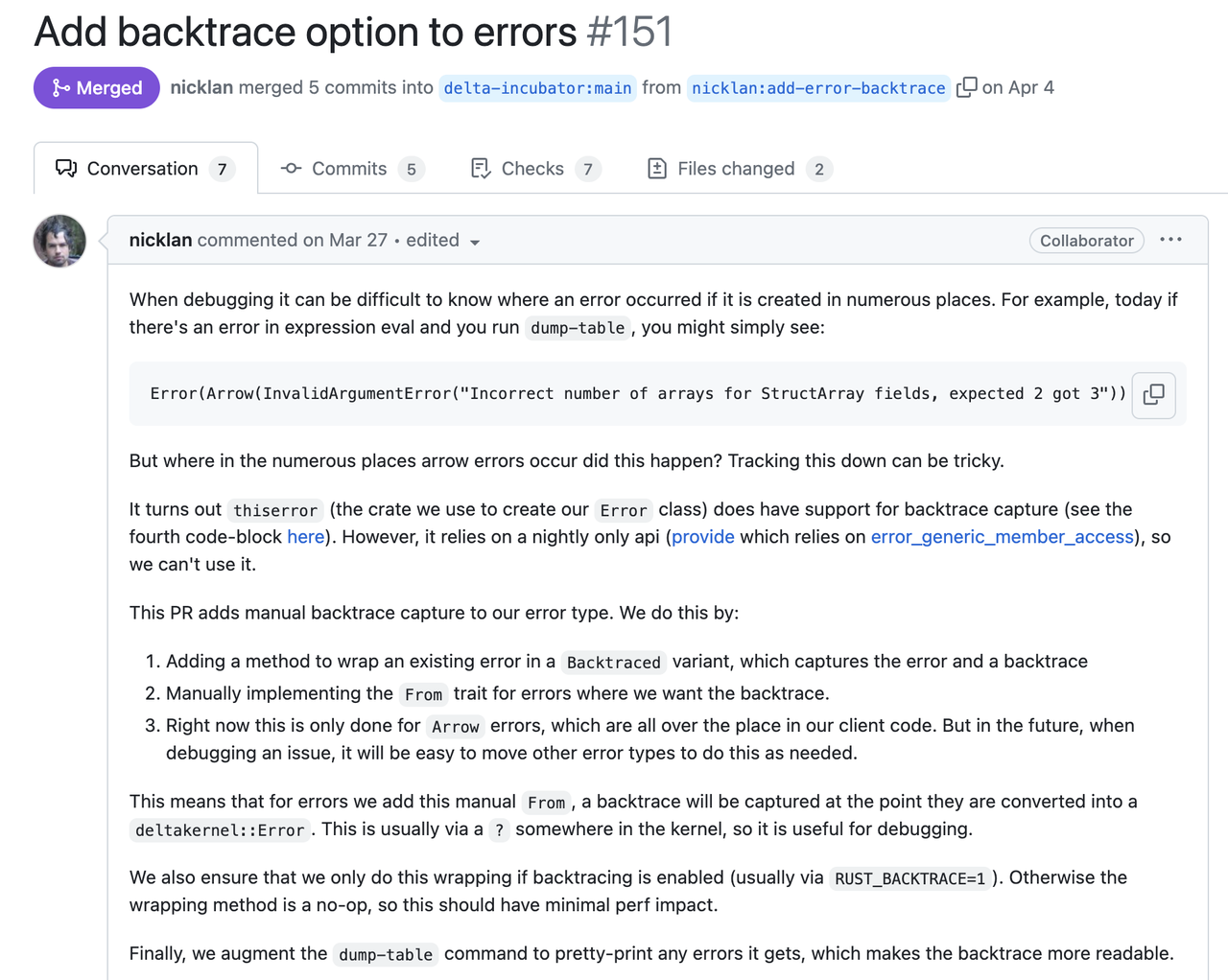
In the following sections, we will focus on the context stack and the way to present errors. And shows the way we implement it. So hopefully you can reproduce the same practices as in GreptimeDB.
System Backtrace
So, now you have the root cause (DecodeMessage(serde_json: invalid character at 1)). But it’s not clear at which step this error occurs: when decoding the header, or the body?
A intuitive thought is to capture the backtrace. .unwrap() is the first choice, where the backtrace will show up when error occurs (of course this is a bad practice). It will give you a complete call stack along with the line number.
Such a call stack contains the full trace, including lots of unrelated system stacks, runtime stacks and std stacks. If you’d like to find the call in application code, you have to inspect the source code stack by stack, and skip all the unrelated ones.
Nowadays, many libraries also provide the ability to capture backtrace on an Error is constructed. Regardless of whether the system backtrace can provide what we truly want, it’s very costly on either CPU (#1261) and memory (#1273).
Capturing a backtrace will significantly slow down your program, as it needs to walk through the call stack and translate the pointer. Then, to be able to translate the stack pointer we will need to include a large debuginfo in our binary. In GreptimeDB, this means increasing the binary size by >700MB (4x compared to 170MB without debuginfo). And there will be many noises in the captured system backtrace because the system can’t distinguish whether the code comes from the standard library, a third-party async runtime or the application code.
There is another difference between the system backtrace and the proposed Stacked Error. System backtrace tells us how to get to the position where the error occurs and you cannot control it, while the Stacked Error shows how the error is propagated.
Take the following code snippet as an example to examine the difference between system backtrace and virtual stack:
async fn handle_request(req: Request) -> Result<Output> {
let msg = decode_msg(&req.msg).context(DecodeMessage)?; // propagate error with new stack and context
verify_msg(&msg)?; // pass error to the caller directly
process_msg(msg).await? // pass error to the caller directly
}
async fn decode_msg(msg: &RawMessage) -> Result<Message> {
serde_json::from_slice(&msg).context(SerdeJson) // propagate error with new stack and context
}System backtace will print the whole call stack, like:
1: <:boxed::box> as core::ops::function::Fn>::call
at /rustc/3f28fe133475ec5faf3413b556bf3cfb0d51336c/library/alloc/src/boxed.rs:2029:9
std::panicking::rust_panic_with_hook
at /rustc/3f28fe133475ec5faf3413b556bf3cfb0d51336c/library/std/src/panicking.rs:783:13
... many lines for std's internal traces
22: tokio::runtime::task::raw::RawTask::poll
at /home/wayne/.cargo/registry/src/index.crates.io-6f17d22bba15001f/tokio-1.35.1/src/runtime/task/raw.rs:201:18
... many lines for tokio's internal traces
32: std::thread::Builder::spawn_unchecked_::{{closure}}::{{closure}}
at /rustc/3f28fe133475ec5faf3413b556bf3cfb0d51336c/library/std/src/thread/mod.rs:529:17
... many lines for std's internal tracesAs you can see, it includes a lot of internal stacks that you are uninterested in.
For other complex logic like batch processing, where errors may not be propagate immediately but be holded for a while, virtual stack can also help making it easy to understand. System backtrace is captured in place when the leaf error is generated, like in the middle step of a map-reduce logic. But with virtual stack, you can postpone the timing to or after reduce step, where you have more information about the overall task.
Virtual User Stack
Now let’s introduce the virtual user stack. The word “virtual” means the contrast of the system stack. Means it’s defined and constructed fully on user code. Look closer into the previous example:
0: Failed to handle incoming content, query: blabla, at src/protocol/handler.rs:89:22
1: Failed to reading next message at queue 5 of 10, at src/protocol/loop.rs:254:14
2: Failed to decode `01010001001010001` to ProtocolHeader, at src/protocol/codec.rs:90:14
3: serde_json(invalid character at position 1)A stack layer is composed of 3 parts: [STACK_NUM]: [MSG], at [FILE_LOCATION]
- Stack num is the number of this stack. Smaller number means outer error layer. And starts from 0 of course.
- Message is the message related to one layer. This is scraped from the
std::fmt::Displayimplementation of that error. Developers can attach useful context here, like the query string or loop counter. - File location is the location where one error is generated (and propagated, for intermediate error layer). Rust provides
file!,line!andcolumn!macros to help get that information. And the way we display it is also considered, most editors can jump to that location directly.
In practice, we utilize snafu::Location to gather the code location. So each location points to where the error is constructed. Through this chain we know how this error is generated and propagated to the uppermost.
Here is what it looks like all together from the code side:
#[derive(Snafu)]
pub enum Error {
#[snafu(display("General catalog error: "))] // <-- the `Display` impl derive
Catalog {
location: Location, // <-- the `location`
source: catalog::error::Error, // <-- inner cause
}
}Besides, we implemented a proc-macro stack_trace_debug to scrape necessary information from the Error’s definition and generate the implementation of the related trait StackError, which provides useful methods to access and print the error:
pub trait StackError: std::error::Error {
fn debug_fmt(&self, layer: usize, buf: &mut Vec<String>);
fn next(&self) -> Option<&dyn StackError>;
fn last(&self) -> &dyn StackError where Self: Sized { ... }
}This proc-macro mainly does two things:
By the way, we have added Location and display to all errors in GreptimeDB. This is the hard work behind the methodology.
Macro Details
Error is a singly linked list, like an onion from outer to inner. So we can capture an error at the outermost and walk through it.
One tricky thing we did here is about how to distinguish internal and external errors. Internal errors all implement the same trait ErrorExt which can be used as a marker. But depending on this requires a downcast every time. We avoid this extra downcast call by simply giving a different name to them and detect in our macro.
As shown below, we name all external errors error and all internal errors source. Then return None on implementing StackError::next method if we find an error, or Some(source) if we read source.
#[derive(Snafu)]
#[stack_trace_debug]
pub enum Error {
#[snafu(display("Failed to deserialize value"))]
ValueDeserialize {
#[snafu(source)]
error: serde_json::error::Error, // <-- external source
location: Location,
},
#[snafu(display("Table engine not found: {}", engine_name))]
TableEngineNotFound {
engine_name: String,
location: Location,
source: table::error::Error, // <-- internal source
}
}The method StackError::debug_fmt is used to render the error stack. It would be called recursively in the generated code. Each layer of error will write its own debug message to the mutable buf. The content will contain error description captured from #[snafu(display)] attribute, the variant arm type like TableEngineNotFound and the location from the enumeration.
Given we already defined our error types in that way, adopting stack error doesn’t require too much work, only adding the attribute macro #[stack_trace_debug] to every error type would be enough.
Present Error to End Users
So far, we’ve covered most aspects. Now, let’s delve into the final piece which is how to present errors to your users.
Unlike system developers, users may not care about the line number and even the stack. What information, then, is truly beneficial to end users?
This topic is very subjective. Still taking the above error as an example, let’s consider which parts would or should users care about:
Failed to handle protocol
0: Failed to handle incoming content, query: blabla, at src/protocol/handler.rs:89:22
1: Failed to reading next message at queue 5 of 10, at src/protocol/loop.rs:254:14
2: Failed to decode `01010001001010001` to ProtocolHeader, at src/protocol/codec.rs:90:14
3: serde_json(invalid character at position 1)The first line gives a brief description of this error, i.e., what users actually saw from the top layer. We should keep it as well. Line 2 and line 3 are about internal details, which are too verbose to include. Line 4 is the leaf internal error, or the boundary from internal code to external dependency. It might sometimes contain useful information, so we count it in. However, we only include the error description since the stack number and code location are useless to users. Then the last line is external error, which is usually the root cause and we’d also include it.
Let’s assemble the pieces we just picked. The final error message presents to users is as follow:
Failed to handle protocol - Failed to decode `01010001001010001` to ProtocolHeader (serde_json(invalid character at position 1))This can be achieved easily with previous StackError::next and StackError::last. Or you can customize the format you want with those methods.
Our experience is that the leaf (or the innermost) error’s message might be useful as it is closer to what really goes wrong. The message can be further divided into two parts: internal and external, where the internal error is those defined in our codebase and the external is from dependencies, like serde_json from the previous example. The root (or the outermost) error’s category is more accurate as it comes from where the error is thrown to the user.
In short, the error message scheme we proposed is:
KIND - REASON ([EXTERNAL CAUSE])Cost?
The virtual stack is sweet so far, and it proves to be both more cost-effective and accurate compared to the system backtrace. So what is the cost?
As for runtime overhead, it only requires some string format for the per-level reason and location.
It’s even better in binary size. In GreptimeDB’s binary, the debug symbols occupied ~700MB. As a comparison, the strip-ed binary size is around 170MB, with .rodata section size 016a2225 (~22.6M), and the .text section occupies 06ad7511 (~ 106.8M).
Removing all Location reduces the .rodata size to 0169b225 (still ~22.6M, changes are very small) and the overall binary size to 170MB, while removing all #[snafu(display)] reduces the .rodata size to 01690225 (~22.5M) and the overall binary size to 170MB.
Hence, the Stacked Error mechanism’s overhead to binary size is very low (~100K).
Conclusion and Future Works
In this post, we present how to implement a proc-macro stack_trace_debug and use it to assemble a low-overhead but still powerful stacked error message. It also provides a convenient way to walk through the error chain, to help render the error in different schema for different purposes.
This macro is only adopted in GreptimeDB now, we are attempting to make it more generic for different projects. A wide adoption of this pattern can also make it even more powerful by bridging third-party stacks and detailed reasons.
Besides, std::error::Error now provides an unstable API provide, that allows getting a field in a struct. We can consider using it in refactoring our stack-trace utils.
About Greptime
We help industries that generate large amounts of time-series data, such as Connected Vehicles (CV), IoT, and Observability, to efficiently uncover the hidden value of data in real-time.
Visit the latest version from any device to get started and get the most out of your data.
- GreptimeDB, written in Rust, is a distributed, open-source, time-series database designed for scalability, efficiency, and powerful analytics.
- GreptimeCloud is a fully-managed cloud database-as-a-service (DBaaS) solution built on GreptimeDB. It efficiently supports applications in fields such as observability, IoT, and finance. The built-in observability solution, GreptimeAI, helps users comprehensively monitor the cost, performance, traffic, and security of LLM applications.
- Vehicle-Cloud Integrated TSDB solution is tailored for business scenarios of automotive enterprises. It addresses the practical business pain points that arise when enterprise vehicle data grows exponentially.
If anything above draws your attention, don’t hesitate to star us on GitHub or join GreptimeDB Community on Slack. Also, you can go to our contribution page to find some interesting issues to start with.



