When it comes to running a database for development, testing, demos, or short-lived workloads, cost and complexity can be big headaches. Traditional database hosting—like a VPS, a cloud VM, or a managed service—comes with ongoing costs, storage expenses, and configuration overhead. You often end up paying for resources even when you’re not using them.
But what if you could spin up a database only when you need it, leverage cheap (or free) object storage for persistence, and tear it down afterward at nearly zero cost, without losing data? One possible approach is to use GitHub Actions as an ephemeral compute environment, combined with S3 (or an S3-compatible service) as persistent storage. With a secure tunnel, you can even access it publicly.
Important Note on Usage:
This approach should be used only for short-term integration tests, temporary demos, or quick development tasks.
Do not abuse GitHub Actions by running a database continuously or using it as a long-term service platform. GitHub Actions is designed primarily for CI/CD, not as a free computing resource for persistent services. If you need continuous or long-running database hosting, please consider other services or set up a Self-Hosted GitHub Runner in an environment you control, ensuring compliance with GitHub’s usage policies.
Key Idea
The core concept is:
- Ephemeral Compute from GitHub Actions: Spin up a MySQL-compatible database only on-demand as part of a CI/CD or testing workflow.
- S3-Compatible Storage for Persistence: Store all database data in object storage like AWS S3 or Cloudflare R2. When the ephemeral environment ends, you still have your data safely stored off-runner.
- Tunneling for Public Access: Temporarily expose the database to the internet for tests or demos.
- Short-Term Use Only: The database runs during the workflow execution window. Once done, the workflow ends and the ephemeral compute resource is freed. This is not intended as a permanent hosting solution.
Want it entirely free? Consider an S3-compatible service like Cloudflare R2 with a generous free tier.
Use Cases
- Integration Testing in CI/CD: Spin up a real MySQL-compatible environment for test runs, then shut it down.
- Temporary Demos: Need a quick, shareable DB instance for a one-off demo? Perfect.
- Short-Term Development: Quickly test new code against a real DB environment without maintaining a full-time service.
Not Recommended For:
- Long-term database hosting or production workloads.
- Maintaining an always-on public database endpoint.
- Circumventing GitHub Actions usage policies.
If you have longer-running needs, consider setting up a Self-Hosted Runner where you manage resources and adhere to the appropriate usage rules.
Example GitHub Actions Workflow
Below is an example GitHub Actions workflow that demonstrates this approach. The workflow briefly spins up a WeSQL database, uses object storage for persistence, and provides temporary tunnel access.
If you want to use this workflow, you can follow the steps in the README.
name: Start WeSQL Cluster
on:
workflow_dispatch:
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Configure AWS CLI
run: |
aws configure set aws_access_key_id ${{ secrets.WESQL_OBJECTSTORE_ACCESS_KEY }}
aws configure set aws_secret_access_key ${{ secrets.WESQL_OBJECTSTORE_SECRET_KEY }}
aws configure set default.region ${{ secrets.WESQL_OBJECTSTORE_REGION }}
- name: Start WeSQL Server
run: |
export WESQL_OBJECTSTORE_BUCKET=${{ secrets.WESQL_OBJECTSTORE_BUCKET }}
export WESQL_OBJECTSTORE_REGION=${{ secrets.WESQL_OBJECTSTORE_REGION }}
export WESQL_OBJECTSTORE_ACCESS_KEY=${{ secrets.WESQL_OBJECTSTORE_ACCESS_KEY }}
export WESQL_OBJECTSTORE_SECRET_KEY=${{ secrets.WESQL_OBJECTSTORE_SECRET_KEY }}
docker run -itd --network host --name wesql-server \
-p 3306:3306 \
-e MYSQL_CUSTOM_CONFIG="[mysqld]\n\
port=3306\n\
log-bin=binlog\n\
gtid_mode=ON\n\
enforce_gtid_consistency=ON\n\
log_slave_updates=ON\n\
binlog_format=ROW\n\
objectstore_provider='aws'\n\
repo_objectstore_id='tutorial'\n\
objectstore_bucket='${WESQL_OBJECTSTORE_BUCKET}'\n\
objectstore_region='${WESQL_OBJECTSTORE_REGION}'\n\
branch_objectstore_id='main'" \
-v ~/wesql-local-dir:/data/mysql \
-e WESQL_CLUSTER_MEMBER='127.0.0.1:13306' \
-e MYSQL_ROOT_PASSWORD=${{ secrets.WESQL_ROOT_PASSWORD }} \
-e WESQL_OBJECTSTORE_ACCESS_KEY=${WESQL_OBJECTSTORE_ACCESS_KEY} \
-e WESQL_OBJECTSTORE_SECRET_KEY=${WESQL_OBJECTSTORE_SECRET_KEY} \
apecloud/wesql-server:8.0.35-0.1.0_beta3.38
- name: Wait for MySQL port
run: |
for i in {1..60}; do
if nc -z localhost 3306; then
echo "MySQL port 3306 is ready!"
exit 0
fi
echo "Waiting for MySQL port 3306..."
sleep 5
done
echo "Timeout waiting for MySQL port 3306"
exit 1
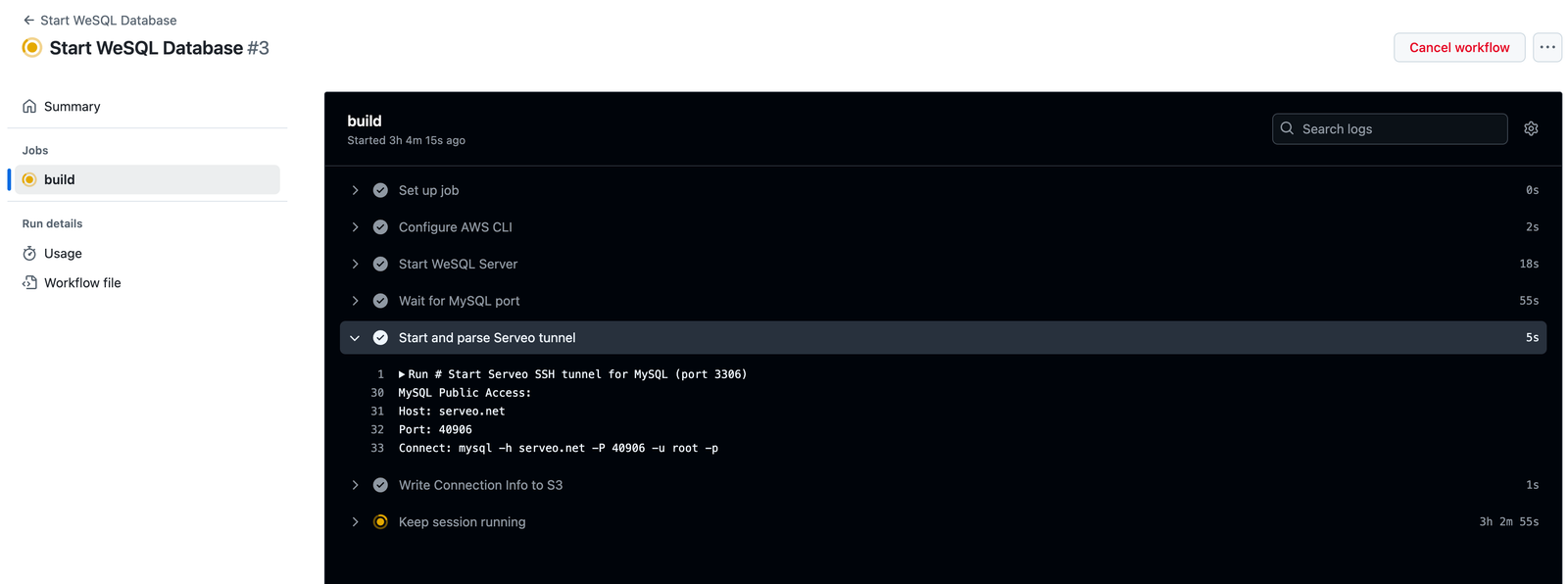
- name: Start and parse Serveo tunnel
run: |
# Just a neat trick: start a tunnel and parse out the assigned port
nohup ssh -o StrictHostKeyChecking=no -R 0:localhost:3306 serveo.net > serveo.log 2>&1 &
sleep 5
TUNNEL_LINE=$(grep 'Forwarding TCP' serveo.log || true)
if [ -z "$TUNNEL_LINE" ]; then
echo "No forwarding line found"
exit 1
fi
HOST="serveo.net"
PORT=$(echo "$TUNNEL_LINE" | sed 's/.*Forwarding TCP connect from .*:\([0-9]*\)/\1/')
echo "MySQL Public Access:"
echo "Host: $HOST"
echo "Port: $PORT"
echo "Connect: mysql -h $HOST -P $PORT -u root -p${{ secrets.WESQL_ROOT_PASSWORD }}"
echo "HOST=$HOST" >> $GITHUB_ENV
echo "PORT=$PORT" >> $GITHUB_ENV
- name: Write Connection Info to S3
run: |
# Just a convenience: store connection info in S3 so you can find it later
cat << EOF > connection_info.txt
host=$HOST
port=$PORT
username=root
password=${{ secrets.WESQL_ROOT_PASSWORD }}
mysql_cli="mysql -h $HOST -P $PORT -u root -p${{ secrets.WESQL_ROOT_PASSWORD }}"
EOF
aws s3 cp connection_info.txt s3://${{ secrets.WESQL_OBJECTSTORE_BUCKET }}/connection_info.txt
echo "Connection info is now in s3://${{ secrets.WESQL_OBJECTSTORE_BUCKET }}/connection_info.txt"
- name: Keep session running
run: |
# Keep the workflow alive so the database stays accessible.
echo "Press Ctrl+C or cancel the workflow when done."
tail -f /dev/null
Breakdown of the Workflow (Tips & Tricks)
- Using S3 or R2: By default, this example shows AWS S3. But since WeSQL just needs an S3-compatible API, you could easily switch to Cloudflare R2’s free tier. That could make the whole setup cost zero, no matter how often you run it.
- Tunneling: Serveo is a neat trick. By using SSH, we ask Serveo to forward a random high port on their server to our MySQL port on the ephemeral runner. Suddenly, anyone on the internet can connect to our ephemeral DB—cool, right? You can replace Serveo with other tunneling services such as ngrok as you like, but Serveo is simple and free.
- Persistence: Because all data lives in S3 (or R2), the DB can vanish and reappear as needed with full persistence. Think of it as “serverless” MySQL.
- Storing Connection Info in S3: Another trick. Instead of always reading logs, you can fetch the connection details from S3. This is handy if you want to programmatically retrieve connection info for some automation elsewhere.
Connecting to the Database
After this workflow runs, check the Actions log for the Host and Port. On your local machine, just do:
mysql -h serveo.net -P -u root -p
Data Persistence & Restarting
The big win here: When the runner dies, you lose the container, but not the data. Next time you run the workflow, WeSQL pulls data back from your chosen object storage provider (AWS S3, R2, or any S3-compatible service). This means you can treat your DB like a long-lived environment—even though it’s technically ephemeral compute.
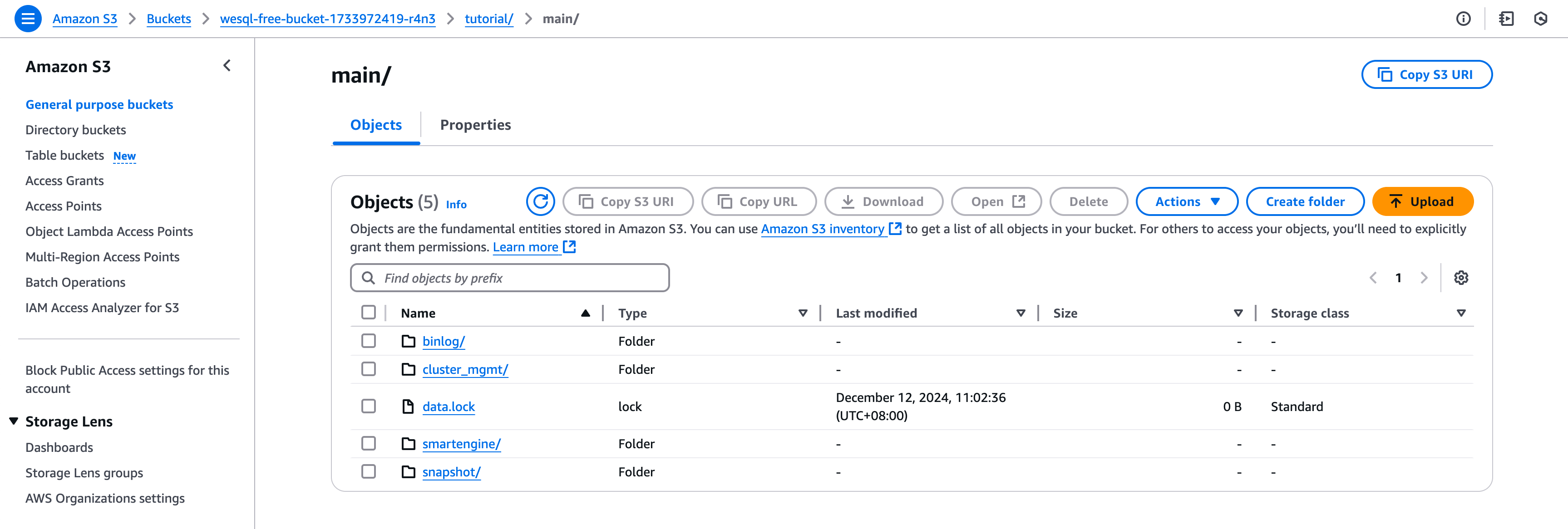
You can see all your data in S3 bucket:
A Note on Security
- The tunnel is public. Use a strong password, maybe restrict access (if the service supports it), and rotate credentials when done.
- Keep AWS and DB credentials in GitHub Secrets, not in your code.
- If you handle sensitive data, consider TLS and additional security layers.
Conclusion
This approach challenges the traditional “rent a server and keep it running” model for databases. Using GitHub Actions as ephemeral compute plus S3 for storage, you get a “serverless-ish” database that runs only when you want it, free of charge, and is still accessible from anywhere on the net.
It’s a neat hack. Give it a try next time you need a throwaway or on-demand DB environment. You might never go back to your old ways of spinning up costly VMs or managed instances just to show someone a quick demo or run a batch of tests.



