PostgreSQL is the bedrock on which many of today’s organizations are built. The versatility, reliability, performance, and extensibility of PostgreSQL make it the perfect tool for a large variety of operational workloads.
The one area in which PostgreSQL has historically been lacking is analytics, which involves queries that summarize, filter, or transform large amounts of data. Modern analytical databases are designed to query data in data lakes in formats like Parquet using a fast vectorized query engine. Relational data is stored in open table formats such as Apache Iceberg, which can support transactions while also taking advantage of the cheap, infinite, durable storage that object stores like S3 provide. Multiple applications can access data directly from storage in a scalable way without losing data consistency or integrity. If only you could have all of that in PostgreSQL…
Today, we are thrilled to announce Crunchy Data Warehouse, a modern, high performance analytics database built into PostgreSQL, initially available as a managed service on AWS via Crunchy Bridge.
Crunchy Data Warehouse brings many ground-breaking new features into PostgreSQL:
- Iceberg tables in PostgreSQL: You can create, manage, query, and update Iceberg tables that are cheaply and durably stored in S3 as easily as PostgreSQL tables, with fast analytical queries, and… perform ACID transactions that span across your operational tables and data lake 🤯.
- High performance analytics: Crunchy Data Warehouse extends the PostgreSQL query planner to delegate part of the query to DuckDB for vectorized execution, and automatically caches files on local NVMe drives. Together these optimizations deliver on average over 10x better performance than PostgreSQL (tuned) in TPC-H queries on the same machine, and even greater improvements on many common query patterns.
- Query raw data files in your data lake: Most data lakes consist of CSV/JSON/Parquet files in S3, which are passed between different systems. You can easily query data files and directories that are already in S3, or insert them into Iceberg tables. You can also query external Iceberg tables, Delta tables, and various geospatial file formats.
- Flexible data import/export: You can load data directly from an S3 bucket or http(s) URL into Iceberg or regular PostgreSQL tables, and you can write query results back to S3 to create advanced data pipelines.
- Seamless integrations: Crunchy Data Warehouse follows the “Lakehouse” architecture and brings together the Iceberg and PostgreSQL ecosystems. External tools can interact with Iceberg tables via PostgreSQL queries, or retrieve data directly from storage.
All of this comes without sacrificing any PostgreSQL features or compatibility with the ecosystem. Crunchy Data Warehouse uses extensions to stay current with the latest version of PostgreSQL (currently 17). Additionally, you can use Crunchy Data Warehouse as both an analytical and operational database for mixed workloads by combining regular tables with Iceberg tables.
You might be wondering: How does Crunchy Data Warehouse differ from other cloud data warehouses?
First and foremost, it’s just PostgreSQL!
You can use all the PostgreSQL tools and extensions you already know and love with Crunchy Data Warehouse, and there are many interesting new synergies between data warehouse features and existing PostgreSQL features.
Crunchy Data Warehouse uses a light-weight, server-based architecture that’s optimized for efficient use of hardware and predictable cost. Performance is very competitive even when querying billions of rows, and you can supplement it with other tools thanks to the open Iceberg format. You can also use standard PostgreSQL features like materialized views to handle more demanding workloads.
We tried to make the experience of using Iceberg tables as simple and smooth as possible. If you already know PostgreSQL, then there is very little you need to learn. Even if you don’t know PostgreSQL, we made it very easy to load your data and start querying.
There are still many features, optimizations, user interfaces, and integrations we are building or planning to build. However, if you’re looking for a simple, batteries-included data stack with one extremely powerful, familiar tool that can serve most of your data needs and has an already-established ecosystem, Crunchy Data Warehouse might be a good choice.
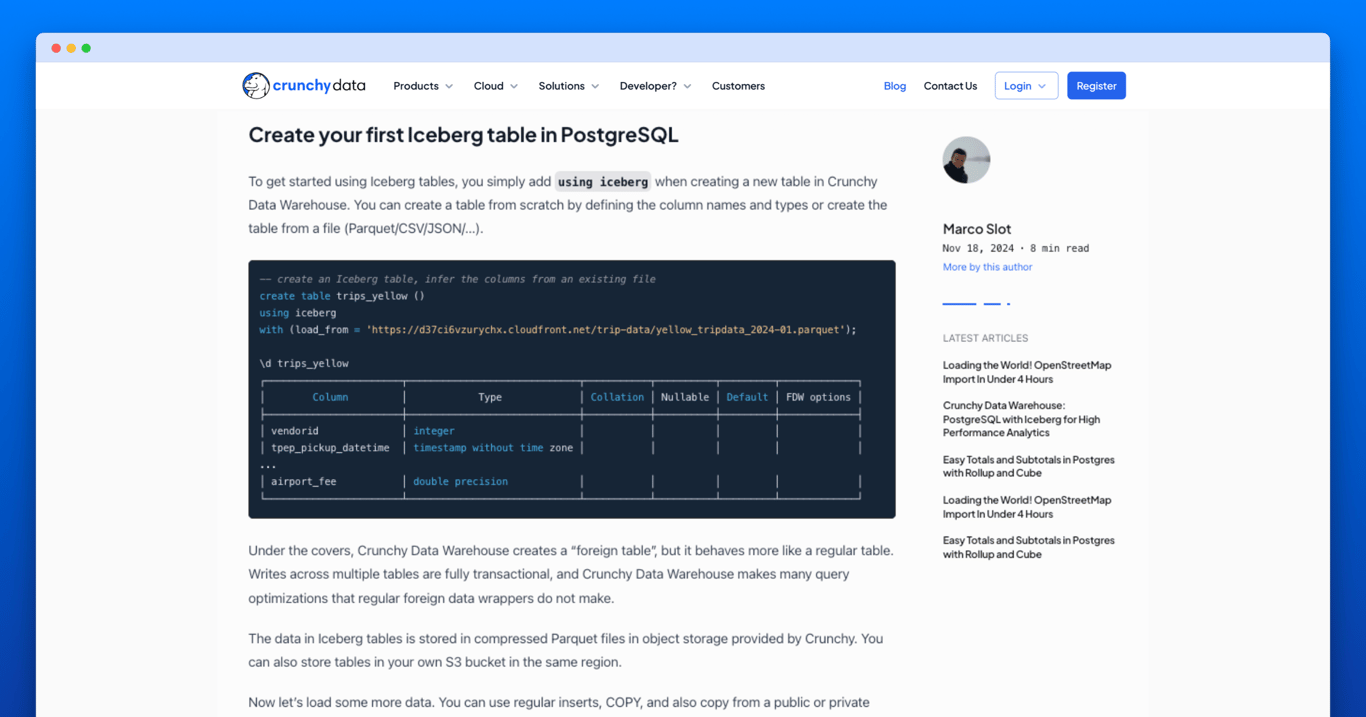
To get started using Iceberg tables, you simply add using iceberg when creating a new table in Crunchy Data Warehouse. You can create a table as usual by defining the column names and types or create the table from a file (Parquet/CSV/JSON/…).
-- create an Iceberg table, infer the columns from an existing file and load it
create table trips_yellow ()
using iceberg
with (load_from = 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-01.parquet');
\d trips_yellow
┌───────────────────────┬─────────────────────────────┬───────────┬──────────┬─────────┬─────────────┐
│ Column │ Type │ Collation │ Nullable │ Default │ FDW options │
├───────────────────────┼─────────────────────────────┼───────────┼──────────┼─────────┼─────────────┤
│ vendorid │ integer │ │ │ │ │
│ tpep_pickup_datetime │ timestamp without time zone │ │ │ │ │
...
│ airport_fee │ double precision │ │ │ │ │
└───────────────────────┴─────────────────────────────┴───────────┴──────────┴─────────┴─────────────┘
The data in Iceberg tables is stored in compressed Parquet files in managed object storage provided by Crunchy. You can also store tables in your own S3 bucket in the same region.
Now let’s load some more data. You can use regular insert and copy statements, and also copy from a public or private URL:
-- load files directly from URLs
copy trips_yellow from 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-02.parquet';
copy trips_yellow from 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-03.parquet';
copy trips_yellow from 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-04.parquet';
copy trips_yellow from 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-05.parquet';
copy trips_yellow from 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-06.parquet';
copy trips_yellow from 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-07.parquet';
copy trips_yellow from 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_2024-08.parquet';
-- or, load files programmatically (and transactionally) in a function or DO block
do $do$
declare month text;
begin
for month in select to_char(m, 'YYYY-MM') from generate_series('2024-02-01', '2024-08-31', interval '1 month') m loop
execute format($$copy trips_yellow from 'https://d37ci6vzurychx.cloudfront.net/trip-data/yellow_tripdata_%s.parquet'$$, month);
end loop;
end
$do$;
Now we’re ready to run our first analytical query. Below is a comparison of running an analytical query on ~26M rows on Iceberg and a regular heap table. Iceberg is >70x faster.

Apart from regular queries, you can also perform inserts, updates, deletes, and schema changes on Iceberg tables.
Small writes (e.g. single-row insert/update) will cause small files to be added to the Iceberg table, which over time reduces performance. You can vacuum the table, which compacts data and metadata files, and deletes files that are no longer used.
-- inserts create small files
create table measurements (station_name text, value double precision) using iceberg;
insert into measurements values ('Arsuz', 24.9), ('Haarlem', 13.4), ('Thessaloniki', 20.3);
insert into measurements values ('Lawrence', 23.4);
insert into measurements values ('Istanbul', 18.5);
-- compact small files in the measurements table
vacuum measurements;
-- or, run vacuum on all Iceberg tables hourly in the current database using pg_cron
select cron.schedule('@hourly', 'vacuum (iceberg)');
In the near future, we’ll add auto-vacuuming of Iceberg tables across all databases.
Most PostgreSQL features are supported out-of-the-box on Iceberg tables (even triggers!). Below is a list of features that are supported and what is still on our road map.
| Supported features for Iceberg tables | Road map for Iceberg tables |
| • Full SELECT/INSERT/UPDATE/DELETE support | • Advanced Iceberg features: hidden partitioning, branching, time travel |
| • Fast data loading via COPY | • Iceberg REST API |
| • Transactions across multiple tables (iceberg and heap) | • External writes to Iceberg catalog |
| • Query using external tools (Spark, pyiceberg, …) | • Indexes |
| • Vacuuming for compaction and data expiration | • Foreign key constraints, unique constraints, exclusion constraints |
| • CREATE TABLE .. USING iceberg AS SELECT .. | • Unlogged/temp tables |
| • Load data directly from CSV/JSON/Parquet/GDAL | • MERGE |
| • Schema changes | • INSERT .. ON CONFLICT |
| • Renames of columns, tables, schemas, databases | • TABLESAMPLE |
| • Views | • SELECT .. FOR UPDATE |
| • Materialized views | • Row-level security |
| • Modifying CTEs | • System columns |
| • Nested data types (arrays, composite types, maps) | • Logical replication |
| • User-defined types | • Materialized views stored in Iceberg |
| • User-defined functions | |
| • Stored procedures | |
| • Prepared statements | |
| • Subtransactions (savepoints, exceptions) | |
| • Triggers | |
| • Check constraints | |
| • Sequences | |
| • Generated columns | |
| • EXPLAIN | |
| • TRUNCATE | |
| • Table-, column-, and view-level access controls | |
| • PostGIS geometry columns | |
| • Joins between Iceberg and heap tables | |
| • Prepared transactions | |
| • Export query results to CSV/JSON/Parquet file in S3 | |
| • Crunchy Bridge managed service features |
As an engineer, one of my favorite Crunchy Data Warehouse features is the fact that transactions that write to multiple Iceberg tables and heap tables are singular ACID transactions.
For instance, you can safely perform transactional data movement operations from a staging table used for low latency inserts into an Iceberg table used for very fast analytics.
-- create a staging table
create table measurements_staging (like measurements);
-- do fast inserts on a staging table
insert into measurements_staging values ('Charleston', 21.3);
Time: 1.153 ms
-- periodically move all the rows from a staging table into Iceberg
select cron.schedule('flush-staging', '* * * * *', $$
with new_rows as (
delete from measurements_staging returning *
)
insert into measurements select * from new_rows;
$$);
By setting up a pg_cron job, transient failures are automatically handled by re-running the job and the atomic behavior of transactions.
You can even safely do unions across the staging table and the iceberg table if you need completely up-to-date query results, without risk of duplicates or missing rows.
-- get the total number of inserted rows across staging table and Iceberg table
select sum(count) from (
select count(*) from measurements_staging
union all
select count(*) from measurements
) all_data;
Finally, adding an analytical query engine to a transactional database comes with many other benefits. For instance, you can easily create a materialized view directly from an Iceberg table or raw data files, you can keep track of which files you imported in incremental processing pipelines, or reliably export a time-partitioned table to S3.
Transactions across operational and analytical tables solve many traditional data engineering problems, and not having to worry about them makes your data stack a lot simpler and more reliable.
You can get started in minutes by signing up for Crunchy Bridge and creating a “Warehouse cluster”. You can then connect using your favorite PostgreSQL client, and consult the Crunchy Data Warehouse documentation for more information. We also made it possible to directly dump and restore your heap tables from any PostgreSQL server into Iceberg tables, so you can immediately compare results.
Crunchy Data Warehouse succeeds Crunchy Bridge for Analytics and includes all of its features. If you are an existing Crunchy Bridge for Analytics customer, you can “resize” your cluster to Crunchy Data Warehouse to add pay-as-you-go managed storage.
If you’re interested in running Crunchy Data Warehouse on-premises, please contact us.



