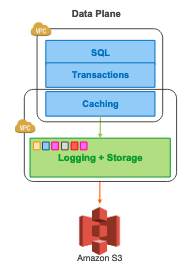
In today’s post, I’m going to look at half of what’s under the covers of Aurora DSQL, our new scalable, active-active, SQL database. If you’d like to learn more about the product first, check out the official documentation, which is always a great place to go for the latest information on Aurora DSQL, and how to fit it into your architecture. Today, we’re going to focus on running SQL and doing transactional reads.
But first, let’s talk scalability. One of the most interesting things in DSQL’s architecture is that we can scale compute (SQL execution), read throughput, write throughput, and storage space independently. At a fundamental level, scaling compute in a database system requires disaggregation of storage and compute. If you stick storage and compute together, you end up needing to scale one to scale the other, which is either impossible or uneconomical.
That’s why, when we launched Aurora 10 years ago (nearly to the day!) we chose an architecture which separated compute and storage (from Amazon Aurora: Design Considerations for High
Throughput Cloud-Native Relational Databases, SIGMOD’17):

As the paper says:
We use a novel service-oriented architecture (see Figure 1) with a multi-tenant scale-out storage service that abstracts a virtualized segmented redo log and is loosely coupled to a fleet of database instances.
In DSQL, we took this pattern one step further: we changed the interface between the SQL executor and storage to remove the need for a large local cache1 right next to the SQL engine. With that out of the way, we could build a new scalable SQL execution layer which can dynamically scale to meet the needs of nearly any workload.
Compute Scale: Lessons from Lambda
Aurora wasn’t the only big launch at re:Invent 2014. Another big one was AWS Lambda2. AWS Lambda brought a new compute scalability model: the ability to scale up efficiently in small units, each with a single well-defined task to do. Since launching Lambda, we’ve learned a lot about how to do fast, efficient, and dynamic compute scalability, and built some really cool technology to make it happen, like the Firecracker VMM3. Firecracker, and all those lessons from building and operating Lambda, allowed us to build a new kind of compute data plane for Aurora DSQL.
Each transaction inside DSQL runs in a customized Postgres engine inside a Firecracker MicroVM, dedicated to your database. When you connect to DSQL, we make sure there are enough of these MicroVMs to serve your load, and scale up dynamically if needed. We add MicroVMs in the AZs and regions your connections are coming from, keeping your SQL query processor engine as close to your client as possible to optimize for latency6.

We opted to use PostgreSQL here because of it’s pedigree7, modularity, extensibility, and performance. We’re not using any of the storage or transaction processing parts of PostgreSQL, but are using the SQL engine, an adapted version of the planner and optimizer, and the client protocol implementation.
Doing Reads
Each DSQL query processor (QP) is an independent unit, that never communicates with other DSQL QPs. On the other hand, DSQL offers strongly consistent, strongly isolated, ACID transactions, which typically requires maintaining lock or latch state across all the compute nodes in the database. In a future post, we’ll get into the detail of how this works, but for now let’s talk about reads.
START TRANSACTION;
SELECT name, id FROM dogs ORDER BY goodness DESC LIMIT 1;
SELECT stock, id FROM treats WHERE stock > 0 ORDER BY deliciousness DESC LIMIT 1;
COMMIT;
This is a read-only transaction. In DSQL, transactions like these are strongly consistent and snapshot isolated4. That means that this transaction needs to get a point-in-time consistent view of the data in both the dogs and treats tables.
To do that, we start every transaction by picking a transaction start time, $\tau_{start}$. We use EC2’s precision time infrastructure which provides an accurate clock with strong error bounds. Then, for each read that the QP does to storage, it asks storage to do that read as of $\tau_{start}$. New writes (with $\tau > \tau_{start}$) can be flowing into the system, we can go to different storage shards or different replicas, but with this interface we’ll always get a consistent view of the state of the database as of $\tau_{start}$. This ensures that we see all transactions committed before $\tau_{start}$, no transactions committed after $\tau_{start}$, no in-flight transactions, and always experience repeatable reads.
At the storage level, these as of reads are implemented using a classic database technique called multiversion concurrency control (MVCC)5, or multiversioning. The storage engine keeps multiple versions of each row, allowing access to old versions (such as the versions most recent as of $\tau_{start}$) without blocking the creation of new versions. In DSQL’s disaggregated distributed architecture this allows us to entirely avoid coordination between replicas on the read path, have as many replicas as we like, and never block other readers or writers on ongoing reads, or readers on ongoing writes.

Another key benefit of this coordination-free approach is that we can send reads to the nearest read replica (in the same region, and generally AZ) to reduce cost and latency. Reads never have to go to a leader or a primary to be sequenced or have their lock state maintained, simply because they don’t have any lock state. This is true in read-only transactions, read-write transactions, and even for the reads triggered by writes (e.g. UPDATE is a read-modify-write).
Avoiding Caching and Coherence
Aurora DSQL uses a logical interface to storage. The QP doesn’t ask for pages, it asks for rows. Knowing the logical structure of the data it holds allows DSQL’s storage to offer quite a high-level interface to the QP: the QP can ask storage to do work like filtering, aggregation, projection, and other common tasks on its behalf. Unlike SQL designs that build on K/V stores, this allows to DSQL to do much of the heavy lifting of filtering and finding data right next to the data itself, on the storage replicas, without sacrificing scalability of storage or compute.
This, in turn, allows us to avoid the scalability bottleneck of having to have a large, coherent, cache8 on-box with SQL execution. In-AZ (or closer) networking, combined with carefully-designed protocols and the ability to push chatty work down, keeps storage fast without the need to cache. We still cache some low-write-rate information (like the list of tables and their definitions).
You can see this in action with EXPLAIN:
explain select key, field0 from usertable where key = 'bob';
QUERY PLAN
------------------------------------------------------------------------------------------
Index Only Scan using usertable_pkey on usertable (cost=100.17..104.18 rows=1 width=64)
Index Cond: (key = 'bob'::text)
Projected via pushdown compute engine: key, field0
Here, the index-only scan on the primary key index on this table (Aurora DSQL tables are index organized) is pushed down to storage, along with the projection of the selected columns. This significantly reduces the number of round-trips between the QP and storage system, with a great impact on performance.
Pushing operations down to storage is a good bet for another reason: Latency Lags Bandwidth. Networks have gotten a lot faster over the last couple decades, but the rate of change of latency has been much slower than the rate of change of bandwidth (partially, this just has to do with speed-of-light limitations). This has been true over multiple decades, and looks set to continue for decades more. That trend means that pushdown, which moves operations close to the storage devices themselves and removes a lot of round-trips, is a good bet for the long-term.
The Big Picture
The overall approach here is disaggregation: we’ve taken each of the critical components of an OLTP database and made it a dedicated service. Each of those services is independently horizontally scalable, most of them are shared-nothing, and each can make the design choices that is most optimal in its domain. This approach is enabled by the extremely fast and reliable networking available in modern data centers, and by designing each component as part of the overall architecture. Tomorrow we’ll go into the write path, which will reveal how the whole picture comes together.
Footnotes
- In most database systems, having a large and fast cache next to the SQL execution engine is critical to performance. Managing and sizing this cache dynamically was one of our biggest innovations in Aurora Serverless, which we talk about in our VLDB’24 paper Resource management in Aurora Serverless.
- I joined the AWS Lambda team in early 2015, a couple months after being completely blown away by this launch.
- You can learn more about Firecracker by checking out our paper Firecracker: Lightweight Virtualization for Serverless Applications from NSDI’20, or checking out the Firecracker source code on Github.
- DSQL’s snapshot isolation level is equivalent to PostgreSQL’s
REPEATABLE READisolation level, because PostgreSQL’sREPEATABLE READlevel is implemented as snapshot isolation (a good choice by the PostgreSQL folks). - MVCC has been around since the late 1970s, described in David Reed’s 1979 PhD thesis Naming and synchronization in a decentralized computer system and Bernstein and Goodman’s 1981 survey of concurrency control techniques Concurrency Control in Distributed Database Systems. Snapshot isolation has also existed since the 1980s, but the most famous formalization is Berenson et al’s 1995 paper A Critique of ANSI SQL Isolation Levels.
- Client interactions with SQL databases are quite chatty, and so tend to be latency sensitive. Most of that is because of the interactive nature of SQL: do some work in the app, do some work in the database, back to the app, back to the database, etc.
- Don’t miss Joe Hellerstein’s Looking back at Postgres if you’d like to understand more about the history and pedigree of Postgres.
- Exercise for the reader who’s interested in cloud database architecture: why do you think we came to the conclusion that we wanted to avoid a coherent shared cache? Compare that to the conclusions in Ziegler et al’s Is Scalable OLTP in the Cloud a Solved Problem? from CIDR’23 which proposes a very different approach to ours.



